在当今数字化时代,获取动态网站成品有时能满足特定的需求。而借助python,我们可以探索多种有效的下载方法。
分析网站结构
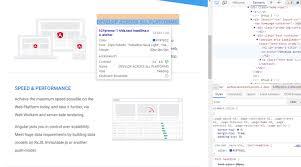
首先,要深入了解目标动态网站的结构。使用python的相关库,如beautifulsoup等,来解析网页的html和css。通过分析页面元素的层级关系、链接走向等,明确我们要下载的核心内容所在位置。这一步是基础,只有清楚网站的架构,后续的下载操作才能有的放矢。
模拟请求
动态网站往往需要与服务器进行交互才能获取完整内容。利用python的requests库模拟http请求,向服务器发送请求获取响应。注意处理可能出现的认证、参数传递等问题。根据网站的要求,正确设置请求头、携带必要的cookie等信息,确保能够获取到最新且正确的页面数据。
处理动态内容
对于包含 动态生成内容的网站,单纯的请求可能无法获取到全部信息。这时可以借助selenium等工具。它能够控制浏览器模拟用户操作,等待 执行完毕后再获取页面内容。通过在浏览器中渲染页面,获取到完整的动态页面数据,包括经过 计算和生成的部分。
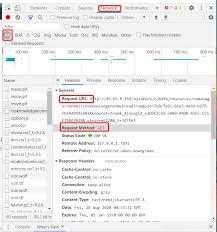
保存下载内容
获取到所需的动态网站数据后,选择合适的方式保存。可以将页面内容保存为html文件,方便后续离线查看。如果网站包含其他资源,如图像、脚本等,也可以一并下载保存到相应目录。利用python的文件操作函数,将获取到的字节流数据写入到本地文件中,确保数据的完整性。
总之,通过运用python进行网站结构分析、请求模拟、动态内容处理以及保存下载内容等多维度操作,我们能够有效地实现对python动态网站成品的下载,满足不同场景下对动态网站数据的需求。无论是为了学习研究、数据备份还是其他目的,这些方法都能帮助我们获取并保留有价值的动态网站信息。
